开云(中国)Kaiyun·官方网站 - 登录入口ChatGPT初次向通盘效户免费提供推理模子-开云(中国)Kaiyun·官方网站 - 登录入口
发布日期:2026-04-04 09:12 点击次数:100

DeepSeek这条“鲶鱼”,让行家大模子竞赛进一步提速。
北京时代2月1日凌晨,OpenAI发布全新推理模子o3-mini。据先容,o3-mini是其推理模子系列中最新、最具老本效益的模子,包含low、medium和high三个版块,仍是上线了ChatGPT和API。值得着重的是,ChatGPT免用度户可以通过在音书裁剪器中选用“推理(Reason)”或再行生成反应来试用o3-mini模子,这亦然OpenAI初次向免用度户提供推理模子。
此前,DeepSeek因推出了性能细腻、开源且免费的V3和R1模子而受到鄙俗暖热,也由于便宜的模子检会老本而走出了一条私有的谈路,通过开源重构了行家的AI竞争步地,使低老本蜕变成为颠覆行业的蜕变旅途。当年一周多的时代里,国表里大模子厂商从“紧要上线”新模子,到降价、免费,千般措施标明,在DeepSeek的刺激下,AI大模子行业的竞争正变得越来越强烈。
OpenAI紧要上线新模子
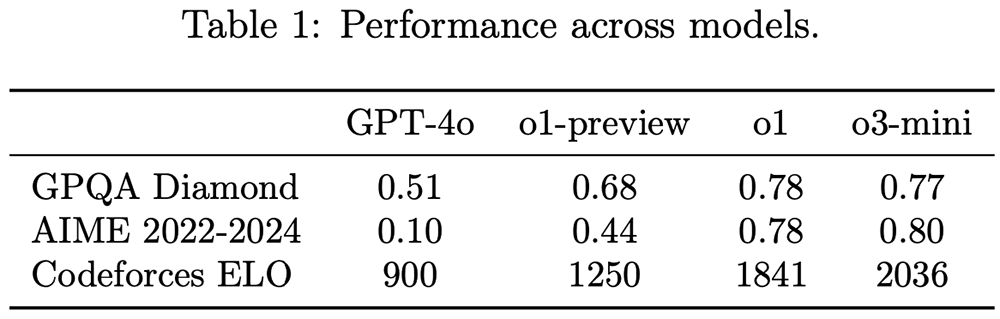
据先容,o3-mini是其最新、最具老本效益的模子,复杂推理和对话身手显赫晋升,在科学、数学、编程等限制的性能卓越了o1模子,并保握了低老本及低蔓延的特色。
具体来看,o3-mini在GPQADiamond(理化生)、AIME2022-2024(数学)、CodeforcesELO(编程)基准测试中,得分分辨为0.77、0.80、2036,并列或是进步了o1推理模子。在中等(medium)推理身手下,o3-mini在额外的数学和事实性评估中阐扬更为出色。同期,o3-mini的平均反应速率为7.7秒,比o1-mini的10.16秒平均反应速率快24%。
值得着重的是,DeepSeek的网页及迁徙把握端均罢了了模子与鸠合的诱骗,赈济联网搜索功能,而o1模子则尚未罢了联网搜索功能。另外,与其他模子凯旋提供问题谜底不同,DeepSeek的R1推理模子可以向用户展示出具体的想考经由。不少用户暗示,在与DeepSeek互动的经由中,赏玩其想考的经由以至比最终取得的谜底更具有启发性。
或是受DeepSeek的影响,o3-mini可与联网搜索功能搭配使用,并展示圆善的想考经由。奥特曼在其外交平台上先容o3-mini时候不仅暗示这是一款“贤慧、反应快速的模子”,还特殊强调,“它粗略搜索网页,还可以展示搜索经由”。

使用权限方面,ChatGPT初次向通盘效户免费提供推理模子,用户可以通过在音书裁剪器中选用“推理(Reason)”或再行生成反应来试用o3-mini模子。ChatGPTPro用户可以无尽拜谒,Plus和Team用户的速率方法从底本o1-mini的每天50条音书增多3倍到o3-mini的每天150条音书。
在订价方面,o3-mini每百万token的输入(缓存未射中)/输出价钱为1.10好意思元/4.40好意思元,比圆善版o1便宜93%。不外,o3-mini的性价比或依然比不上DeepSeek。手脚对比,DeepSeek的API提供的R1模子,每百万token的输入(缓存未射中)/输出价钱仅为0.55好意思元/2.19好意思元。
好意思国知名播客主握东谈主LexFridman在其个东谈主外交平台上暗示,固然OpenAI的o3-mini阐扬可以,可是DeepSeek的R1以更低老本罢了了同等的性能,并创始了通达模子透明度的先河。
DeepSeek让大模子“卷”起来了
记者着重到,早在几天以前,奥特曼在修起DeepSeek的爆火时就指出,DeepSeekR1让东谈主印象真切,尤其有计划到老本方面,“但咱们无疑将带来更好的模子,咱们很快会发布新的模子”。业内东谈主士分析称,o3-mini模子的紧要上线,或标明OpenAI已感受到了来自竞争敌手的压力,需要加速发布性能更强的模子施展注解本人的最初上风。
值得着重的是,在o3-mini推出后,OpenAI首席实施官山姆·奥特曼与一众高管在reddit上回答网友的问题。奥特曼承认,中国竞争敌手DeepSeek的崛起缩小了OpenAI的时期最初上风。“DeepSeek是个非凡优秀的模子。咱们将接续推出更优质的模子,但将无法保管往年的最初上风”。
关于“更优质的模子”,奥特曼暴露,下一代推理模子o3将在“数周密月内”发布。但被业界期待了许久的旗舰模子GPT-5,则尚无发布的时代表。
除此除外,奥特曼冷漠地对开源与闭源的问题进行了修起。他指出,OpenAI当年在开源方面站在“历史失实的一边”,公司也曾开源部分模子,但主要选用闭源的建树模式,畴昔将再行制定开源政策。
OpenAI首席居品官KevinWell还暗示,公司正有计划将非前沿的旧模子如GPT-2、GPT-3等开源。
在OpenAI发布新模子的同期,国产大模子的降价波涛仍在握续。1月30日,阿里云发布百真金不怕火qwen-max系列模子挽救告知,qwen-max、qwen-max-2025-01-25、qwen-max-latest三款模子输入输出价钱挽救,qwen-maxbatch和cache同步降价。
而就在1月29日凌晨,阿里云才庄重发布升级了通义千问旗舰版模子Qwen2.5-Max,据先容,Qwen2.5-Max模子是阿里云通义团队对MoE模子的最新探索后果,预检会数据进步20万亿tokens,展现出极强劲的概述性能,在多项公开主流模子评测基准上录得高分,全面卓越了包括DeepSeek-V3在内在当今行家最初的开源MoE模子以及最大的开源隆盛模子。
天风海外分析师郭明錤觉得,当今从生成式AI趋势中赚钱的形状,主要照旧“卖铲子”和镌汰老本,而不是创造新业务或晋升既有业务的附加值。而DeepSeek-R1的订价策略,会带动生成式AI的全体使用老本着落,这有助于增多AI算力需求,而且可以镌汰投资东谈主对AI投资能否赚钱的疑虑。不外,使用量的晋升进度能否对消价钱镌汰带来的影响仍然有待不雅察。同期,郭明錤暗示,唯一大批部署者才会遭受Scalinglaw边缘效益的放缓,因此当边缘效益再度加速时,英伟达将依然是赢家。
 海量资讯、精确解读,尽在新浪财经APP
海量资讯、精确解读,尽在新浪财经APP
背负裁剪:赵想远 开云(中国)Kaiyun·官方网站 - 登录入口